
Are my services talking to each other?
I am faced with an interesting thought experiment, which asks:
If I can see two of my friends, and I know they should be communicating to each other, what is the simplest way of making sure they are doing so?
Your first instinct is to look at them and listen. What if the communication method is subtler than that? What if you are, metaphorically speaking, deaf, and cannot eavesdrop on their conversation?
A problem like arises when you have a non-trivial amount of distributed components talking to each other, forming a complex network. Let’s start from the basics and consider a simple one:

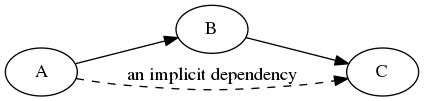
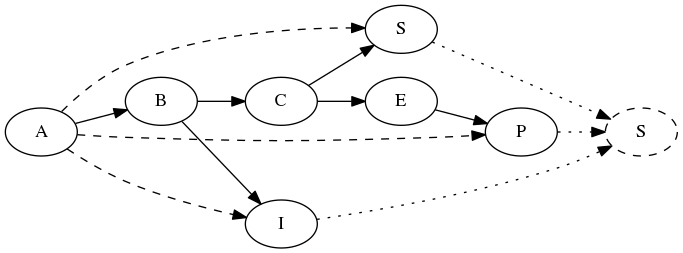
arrows indicate flows of information, i.e. x → y means x sends information to y
You could assume A is an event log, for example, of financial transactions; B is a message queue and C is a fast queryable cache for the transactions. We want to be able to query the cache quickly for log events and rely on the message queue of transporting them from A to C, while preferably not having a hard software dependency from A to C.
The illusion is that while there are neither code nor protocol dependencies between A and C, a semantic dependency exists: the one in our heads! A is content on dumping information towards B, but what we’re really interested in is messages getting through all the way to C. So in reality, if we superimpose our perceived dependencies on top of information flows, we end up with this:
Tolerating faults
What if the chain breaks? What happens when A can’t push messages onward to B, and we get a blackout? Who gets notified? C doesn’t know what’s happening in A, it’s just not getting information! In line of the original question, if I can see both A and C are doing fine, but they’re not talking to each other, where is or who is the broken phone?
With such a simple case as above, pointing this out is easy, so let’s make our network a bit more complicated.
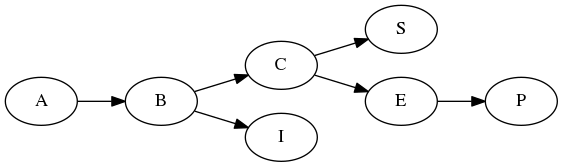
A - an event log; B - a message queue; C - a cache; E - app back-end; P - a user-facing application; I - a business intelligence system; S - a storage system
Let’s assume each one of these components is an independent service, each load balanced and with redundancies that aren’t visible beyond the node itself1, and that communication is done over a computer network using some protocol.
The depicted network consists of a set of applications that all in one way or the other build on top of an event log, A. In one branch, there’s a fast queryable cache for the transaction log, the app back-end is an interface for the cache (like a REST API), and the storage acts as a long-term backup system. The second branch consists of a business intelligence system that analyzes the event log data and does something with it.
Indirectly, there are dependency arrows emanating from the root of the network tree (A) to its leaves S, P and I. From an observer’s perspective, these are the relationships that matter. These are the implicit dependencies. Furthermore, we can see those dependencies, but we build the code in such a way that it does not! The event log simply dumps data to a message queue, and that’s it. What is worse, is that the implicit dependencies each propagate up the chain. Not only does the leaf node depend on the root node, it also depends on the intermediate nodes.
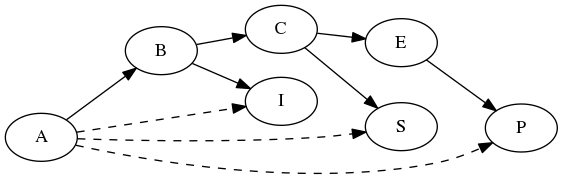
Implicit dependencies
The inherent hazard in all this, of course, is that there’s a communication error. Even though we (hopefully) built the system following the robustness principle, data isn’t flowing from the root node to the leaf nodes and we have to quickly identify where the disconnect happened.
Seeing is not enough
Our first instinct is to peer at the logs. So we go through each edge in the network and see if
there’s a fault. This means for n nodes looking at least at n-1 edges for each fault! Moreover,
the problem isn’t fixed by using something that gives me visibility of the nodes, like ZooKeeper
or other service discovery tools. This is because I am interested in the flow of information from
one node to another. The thought experiment already assumes that the nodes are there, only the
communication between them is broken.
In the Internet world, with the Transmission Control Protocol , communication is made reliable using error-checking and acknowledgments. That means, if A were a network element and wanted to send things over to C, in case of a successful delivery C will acknowledge this back to A.
For various reasons, it may be that in a distributed service network this approach is not feasible. This is the cost of abstractions: when you enforce loose coupling, you have to deal with the consequences of looseness. We could build the transaction log aware of the user-facing Application but that may be overkill.
For the particular problem of acknowledging from a message queue root to a consumer leaf, there are various solutions. You either implement this on your own, which while laborious, essentially follows the principle of error-checking. The caveat is this grows in complexity with every new node. Another option is to use a message queue (one of these things is not like the others) that supports this natively.
The rescue signal
We could build a centralized logging system to which each node logs its events. This centralized
system contains all events from all nodes. To make the data meaningful, you need to construct a
way to determine the flow of information, that is, grouping events together semantically. Worse, the
system will require manual or semi-automated inspection to determine when any event is missing its
acknowledgment, that is, A logged an event of sending Foo to message queue but the user
application back-end E never processed it.
A system like this could work using a FRP approach: since FRP signals map exactly to discrete events, one could build a rule engine. By integrating time flow and compositional events, a centralized system could use its rule engine to listen to signals. A signal can be any event, e.g., a financial transaction that was logged into the event log. You can combine this signal with another event in a system that consumes transactions and does something with them, like the business intelligence system. The sum of these two signals imply that “a financial transaction was consumed by the business intelligence system”. This is also a signal!
Building a FRP-based rule engine isn’t easy, you’d need to construct a rule engine that can map diverse data events into high-level signals and then create additional logic for summing the signals.
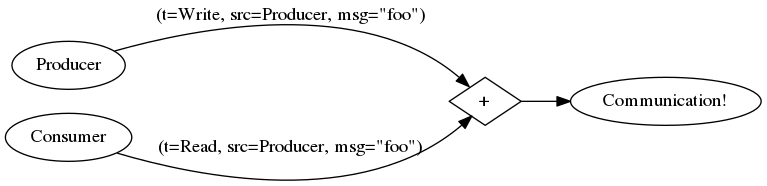
The sum of two signals is another signal. (Oh hey, this makes it a semigroup!)
Once such a system is built, it can be queried to determine the state of the network quite efficiently (and perhaps elegantly), but it does not introduce any fault tolerance and will only tell you where data is moving, but not where it isn’t.
Lurking in the shadows
I guess that most of this stuff underlines the difficulties of unraveling a monolith into a microservice. Keeping track of network traffic is really hard, even at the hardware level (!), so when we push this abstraction to the software level, it is not a surprise that this can cause problems.
Playing with some toy solutions I thought of something I call a shadow network. Let’s say our principal information source is an event monitor X and we have a leaf node in the information dependency tree that is interested in data originating from X.
Each leaf node sends its data to the shadow node. The shadow node understands the data and can tell where it originated from, thereby seeing the implicit dependencies. The shadow node is effectively a mirror of the root node(s).
In the shadow network, X does not receive any new dependencies nor do the intermediaries, but the leaf nodes each push their actions to the shadow node. The shadow node contains a rule engine that can parse leaf events. A rule is something that identifies a source. It could be anything, from a simple parser (“this looks like Apache logs” → “it came from Apache!”) to something more sophisticated. This introduces a dependency only to leaf nodes, but the problem is that the shadow node has to be kept up to date on how to correctly map events to sources. When you change the format of the data traveling across the network, you have to update the rule engine.
Unfortunately, this doesn’t really help us: you can query the shadow node to get the implied dependencies, but that’s it. So while it requires less effort to develop, disregarding cases where creating rules causes difficulties, it suffers from the same flaw than the centralized FRP engine: it can only tell when data is flowing but not when it isn’t.
No easy answers
This makes both solutions rather untenable for monitoring a microservice architecture, but they can be used in cases where the service network grows large and you are working with opaque layers, that is, you don’t know what’s between the leaves and the root, and you want to construct the implicit dependency graph.
Bolting temporal awareness in the shadow network works if the data is supposed to be regular. If the
consuming leaf expects a tick from the origin(s) every n seconds, the shadow rule engine can be
built to be aware of this. If ticks aren’t happening when they are supposed to, you can create a
fault on the implicit dependency. Alas, only regularly occurring data works here, so we’re out of
luck for irregular events.
Either way, the original problem is an interesting one. I suppose the only reliable way of doing things is to do what the Internet Protocol does: acknowledgment and error checking. While certainly a lot of work, it will be reliable. We all love reinventing wheels, don’t we?
My opinion? Don’t fix what isn’t broken! While we all benefit from loose coupling, and while microservices definitely are most of the time an improvement over monoliths, both bring hurdles and challenges of their own. The bottom line is that networking is not easy, and if one forgets this, problems will occur.
-
So for all intents and purposes the nodes represent services as a whole instead of individual physical units, whatever they may be. ↩